Video relighting is a challenging yet valuable task, aiming to replace the background in videos while correspondingly adjusting the lighting in the foreground with harmonious blending. During translation, it is essential to preserve the original properties of the foreground, e.g. albedo, and propagate consistent relighting among temporal frames. While previous research mainly relies on 3D simulation, recent works leverage the generalization ability of diffusion generative models to achieve a learnable relighting of images.
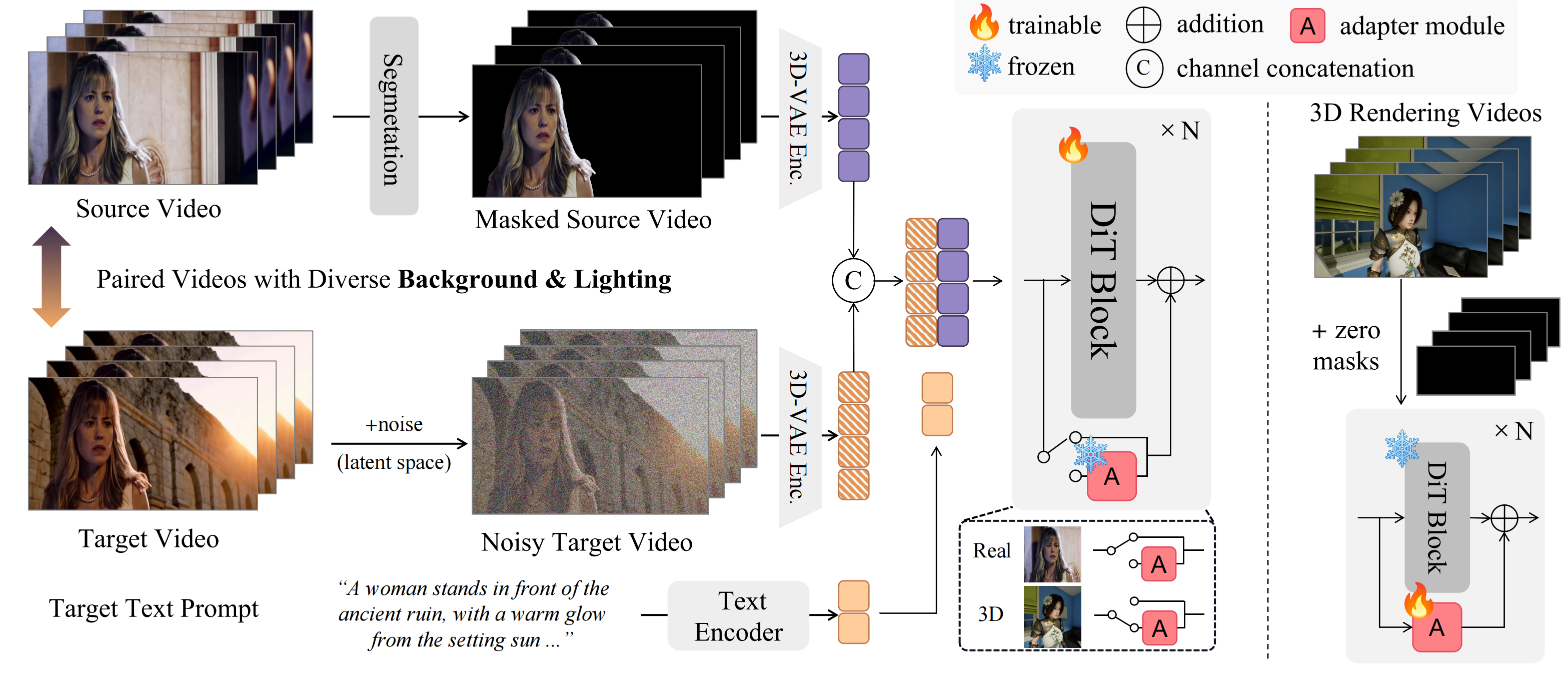
In this paper, we propose Lumen, an end-to-end video relighting framework developed on large-scale video generative models, receiving flexible textual description for instructing the control of lighting and background. Considering the scarcity of high-qualified paired videos with the same foreground in various lighting conditions, we construct a large-scale dataset with a mixture of realistic and synthetic videos. For the synthetic domain, benefiting from the abundant 3D assets in the community, we leverage advanced 3D rendering engine to curate video pairs in diverse environments. For the realistic domain, we adapt a HDR-based lighting simulation to complement the lack of paired in-the-wild videos.
Powered by the aforementioned dataset, we design a joint training curriculum to effectively unleash the strengths of each domain, i.e., the physical consistency in synthetic videos, and the generalized domain distribution in realistic videos. To implement this, we inject a domain-aware adapter into the model to decouple the learning of relighting and domain appearance distribution. We construct a comprehensive benchmark to evaluate Lumen together with existing methods, from the perspectives of foreground preservation and video consistency assessment. Experimental results demonstrate that Lumen effectively edit the input into cinematic relighted videos with consistent lighting and strict foreground preservation.
BibTex Code Here